Introduction
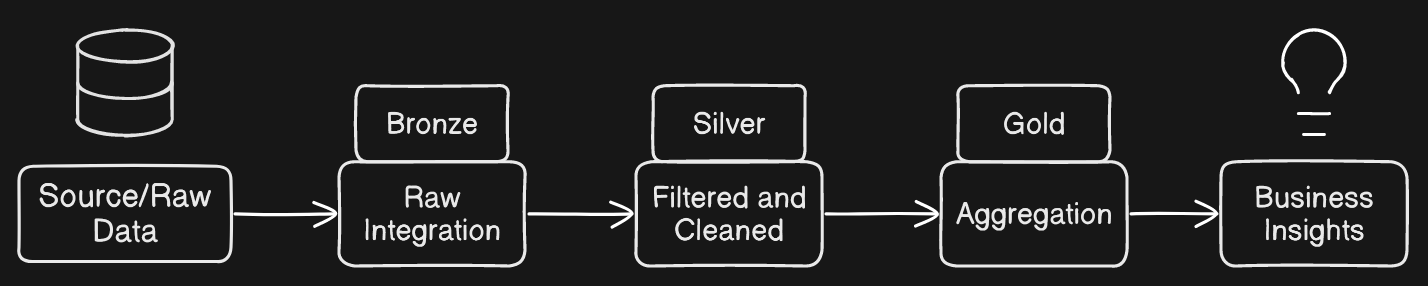
The Medallion Architecture is something that I have learned from a Data Engineering book and it has me interested. It uses a three layer approach where bronze is raw data, silver is data wrangling, and gold for the final product, business level data.
Process
When I am doing the Medallion Architecture or any data pipeline architecture, I see it as a directed acyclic graph (DAG). If we view this in nodes and edges, a “directed” graph means that each edge points in one direction between each node. For example, let’s say we have four nodes. Node 1 is directed to node 2 which is directed to node 3 which is directed to node 4.
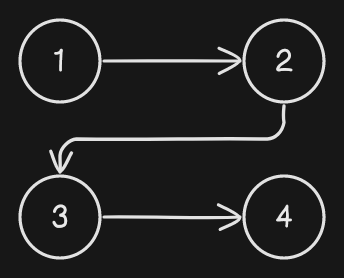
None of the graphs point back to the other node. Node 2 doesn’t point back to node 1, it’s only one direction. This is called downstreaming. Downstreaming is the processes of consuming data from a different process. Upstreaming is the sources or processes of providing data to a different process.
The source data can come from an API, raw local data files, data lake, warehouse, or a lakehouse. It all depends on the needs of the project.
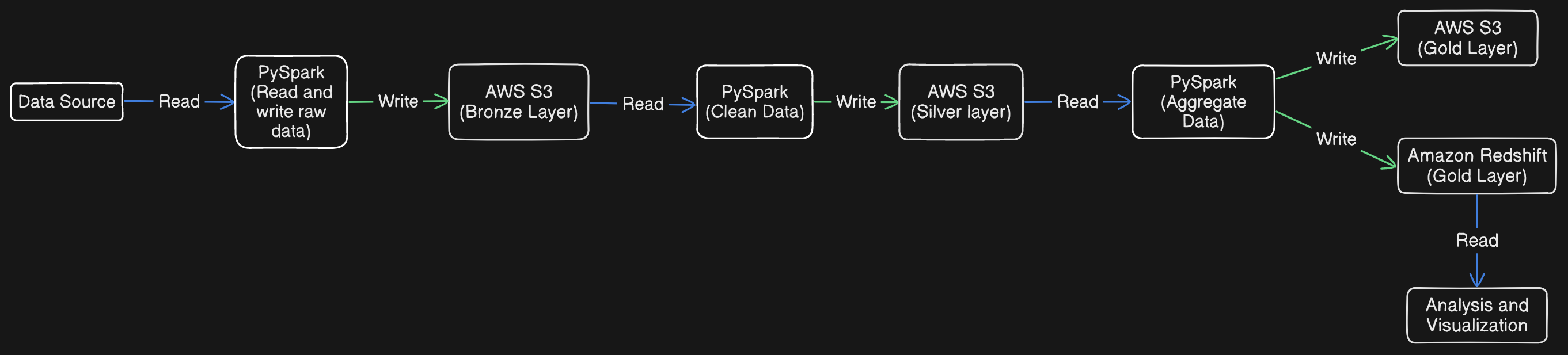
When staging ingested data, if we are using ELT, then ingesting data is the extract and load (read and write) part of ELT. A data lake is usually used for data ingestion. A data warehouse is usually used to aggregate data and for analytics. For our example, we are extracting the raw data from a source, then that data is loaded into a data lake (AWS S3/Bronze Layer), then tranformation/cleaning is applied after data is loaded into data lake, and finally the data is loaded into a data warehouse (Amazon Redshift) for analytics.
For example, let’s say I’m using AWS S3 for the data ingestion. Let’s also say we have raw CSV or parquet data in the S3 bucket. We can read in the data with Spark, or boto3 and pandas, and then save the raw data to the bronze layer in the data lake (AWS S3).
Next, the silver layer. We read in the bronze layer and transform that bronze layer data and write it as preferably parquet format back to AWS S3.
Next, the gold layer. Let’s say we use Amazon Redshift as a data warehouse. We load the silver layer data from AWS S3 and we aggregate the data. Then, we write it to Redshift as a gold layer.
We can also use Airflow or Prefect with this. We can put all those steps in functions and define a DAG. Then, we can use Airflow’s python operators and set task dependencies.
Then, we can use the gold layer data to analyze and visualize our data, and use those visualization and analysis for insights.
Change Data Capture (CDC)
CDC tracks changes in source databases and transfers only changed data instead of batch loading an entire database. For real time data analytics, CDC ensures data is current.
If we wanted to add CDC to the Medallion Architecture, then we need to capture and apply changes from source data to the bronze, silver, and gold layers, which can be achieved using Delta Lake format as it supports ACID (atomicity, consistency, isolation, and durability) compliance.
We can use Debezium for CDC and Delta Lake for handling the data in the data lake.
The first thing we have to do is actually set up Debezium. We can set up Debezium using Docker Compose, configure Debezium connector, and post configuration to their REST API. Now, we can start the process of the Medallion Architecture using PySpark, Debezium, Apache Kafka, AWS S3 (Data Lake), Amazon Redshift (Data Warehouse), Prefect, and Delta tables.
First, we can define the schema of the data. Then, we can use Apache Kafka for reading changes. After that, since we are in the bronze layer, we can parse the JSON data and apply the schema from the loaded data we got from Kafka. Then, we write that to the Delta Lake. And then we clean the data in the silver layer, then write it back to the Delta Lake, and in the gold layer we aggregate the data, and then write it to Amazon Redshift. Finally, we read in the data from Redshift for analysis and visualizations.
[Implementing code Later]